 2018, Vol. 50
2018, Vol. 50引用本文 | doi: 10.16356/j.1005-2615.2018.03.015 |



特征识别技术对于实现CAD与CAPP的有效集成有着关键意义,当前的三维建模软件所绘制的零件仅仅是设计特征的集合,由于设计人员与工艺人员在零件模型理解上的不同,导致工艺人员较难利用设计人员的三维零件模型生成其需要的三维工序模型。传统工艺方法相对落后,存在着信息孤岛,无法有效地继承和利用三维模型的相关信息,工艺数据亦难以用合理的方式表达、获取和管理,特征识别作为零件三维工序模型的快速生成关键技术之一显得尤为重要。
特征识别通过提取分析三维工序模型的几何和拓扑信息,对模型上的生成面选择性组合得到可用于生产加工的制造特征。特征识别对于实现CAD/CAM/CAPP的有效集成具有非常重要的意义。复杂特征如组合特征的识别技术一直是领域内的难题。自特征识别这一概念提出以来,国内外研究人员一直在进行广泛而深入的研究。
目前比较常用的特征识别方法包括逻辑规则(if-then)与专家系统[1]、基于图的方法[2]、凸包体积分解法、基于细胞的体积分解法[1]、基于痕迹[1]的方法以及混合方法。基于图的识别方法最早由Jo shi等[2]提出,旨在建立一个包括拓扑信息和部分几何信息的零件表达式,其核心思想是将实体的边界表示为属性邻接图,采用启发式规则、神经网络和子图同构等方式进行特征识别。基于这一方法的技术已广泛应用于后续的研究中,甚至一些商业化的工艺规划软件也采用了该技术。该方法的优势在于图的表达方式简单明了,可以很好地识别独立特征,缺点是无法识别具有复杂曲面的相交特征,因为特征相交会造成原特征拓扑信息的丢失。凸包和基于细胞体的分解方法[1]均属于体积分解法。此方法先将输入的零件模型分解成一系列的中间凸体,然后使用交替和差分解法(Alternating sum of volum es, ASV)对这些中间凸体进行收敛运算以形成特征并进行类型判断。起初该方法成功地应用于多面体零件,但却无法保证重新组合而成的特征是有效的加工特征,穷举每一种可能组合的计算量太过庞大,计算复杂度也急剧上升。文献[1]在面向对象的特征查找系统(Object -oriented feature finder, OOFF)中率先提出基于痕迹[1]的方法来处理相交特征,该方法是逻辑法和增量体积法的结合。其中三维零件模型的拓扑信息、几何信息和启发式信息等共同构成了特征存在的痕迹,认为特征加工过程中会在零件的边界留下相关的痕迹,通过定义存在性规则完成特征识别,但很难找到正确且合适的特征痕迹,因此也存在不小的局限性。文献[3]提出了最小条件子图法进行相交特征的识别,此方法综合了传统的基于图识别和基于痕迹识别的方法,同时还引入了Marefat等的虚链概念,以扩展属性零件图(Extended attributed adjacency graph, EAAG)的方式表示零件模型,然而该方法无法确保找到所有必需的虚链,还要排除大量错误的特征假设,方法局限于多面体对象,因此无法用于大多数常见特征的识别。
由于特征的创建缺乏统一的规范,这就可能导致同一几何形状的特征存在多种完全不同的生成方法,此外有些特征包含复杂轮廓曲面,难以用初等解析函数完全明确表达出来,故如何对零件模型所包含的几何信息和拓扑信息进行提取和重新融合并迅速地将其转换为制造特征,成为制造特征快速识别的难点。此外,图的大小与特征的复杂程度成正比,搜索空间及候选匹配对序列数量十分庞大,导致已有方法的运行耗时呈指数级增长,特征识别速度较慢。
针对特征识别中遇到的难点以及以上各方法的局限性,本文提出了基于图和子图同构算法的制造特征识别方法(Manufacturing feature graph algorithm, MFGA)。首先分析了典型零件制造特征的特点,确定了可识别制造特征的范围,然后从零件模型文件中提取所需的几何与拓扑信息,生成加权属性邻接图,最后利用改进的子图同构算法辅以特征判定规则完成特征的匹配与识别。
1 典型零件制造特征零件的制造特征指包含加工信息、具有明显制造意义的几何形状部分,是经过相关的工艺方法加工后形成的。例如车削工艺会形成回转表面,典型的有圆柱面、圆锥面等;铣削工艺会形成平面、槽和成形曲面等。由于制造过程中选用的工艺方法不同、刀具种类繁多,最终会形成各类不同的制造特征。
本文将典型零件制造特征简单划分为两类:简单特征与复杂特征,如图 1所示。其中简单特征指无法拆分且拥有加工意义的几何形状部分,主要分为孔、倒角、平面、简单槽腔和初等解析曲面等。复杂特征包括组合特征和自由曲面等,组合特征是由多种基本特征进行组合所得的特征,例如常见的多阶孔、复杂腔槽等;自由曲面通常由曲线和曲面经过自由变化生成,无法用初等解析函数完全明确表达出来,主要指零件模型中的复杂轮廓等特征。

|
图 1 制造特征分类 Figure 1 Classification of manufacturing feature |
在制造过程中,随着既定工序和工步等加工操作的有序完成,零件模型的制造特征亦在不断演变。由毛坯开始渐渐形成简单特征,随着制造过程的进行,其中部分简单特征在经过多次加工操作后,会逐渐向复杂特征演变,因此零件的最终形状可以定义为简单特征和复杂特征的集合。
2 零件信息提取基于三维零件模型制造特征识别的具体过程如图 2所示。显然,欲构建零件的属性邻接图以完成特征识别首先需要提取零件的几何信息与拓扑信息。

|
图 2 零件制造特征识别流程 Figure 2 Recognition process of manufacturing feature |
三维零件模型通常采用B-rep(Boundary representation)方法表示,特征可被定义为零件模型上互相关联的面的集合。基于B-rep的模型其几何与拓扑信息经由面和边形成的图数据结构清晰地表达出来,因此需要根据面、环和边的包含关系逐层提取零件信息。其基本流程分为以下几个步骤:(1)调用实体特征访问函数遍历访问零件模型的所有可见特征并保存;(2)分别调用面、轮廓与边的遍历函数等逐层访问零件模型相应的面、轮廓和边,利用循环语句对每一个面分别调用特征属性值访问函数分别提取出每个面的ID值(标识符)、面的类型、面所包含的所有轮廓以及轮廓上的全部边、边的ID值和边的类型等信息,并将以上所有获取到的信息保存到文件中。零件的各项信息提取流程如图 3所示。

|
图 3 零件模型各项信息提取流程 Figure 3 Information extraction process of part |
遍历模型获取的全部面分别对应属性邻接图中的各个节点,然而由于模型文件中各个面的ID值是任意的,因此使用符号表将N个面节点的ID值与从0到N-1的整数建立一对一映射。通过数组可以快速访问该节点下对应的所有边,与此同时也大大简化了后续的特征匹配与识别过程。
属性邻接图不仅包含了拓扑连接关系,即节点与边的连接关系,而且包含了语义信息,即面节点和边的属性信息,具体指面、边的类型以及边的凹凸性。只有将这些信息全部确定后才能获得零件模型完整的属性邻接图,从而进行特征子图匹配。需要注意的是,Creo使用ACIS为造型内核,其中的圆柱面或圆锥面使用两个等同的半圆柱/圆锥面来表示。若将两个半圆柱/圆锥面均纳入属性邻接图中,会导致边的重复遍历,并且会产生冗余边,故通过其他方法[4]先识别出孔、锥面等轴对称特征,将表示轴对称特征的面和边从属性邻接图中删除,生成新的属性邻接图,然后再进行边的凹凸性[5-8]判定。通过调用相关函数获取包含某条边的两个邻面及其邻接边的ID值,如图 4所示,根据两邻面的法向量N1=(A, B, C)和N2=(X, Y, Z)按式(1)计算出两个面的夹角θ,有
| $ \theta {\rm{ = arccos}}\left( {\frac{{AX{\rm{ + }}BY{\rm{ + }}CZ}}{{\sqrt {{A^{\rm{2}}}{\rm{ + }}{B^{\rm{2}}}{\rm{ + }}{C^{\rm{2}}}} \sqrt {{X^{\rm{2}}}{\rm{ + }}{Y^{\rm{2}}}{\rm{ + }}{Z^{\rm{2}}}} }}} \right) \times \frac{\pi }{{{\rm{180}}}} $ | (1) |

|
图 4 邻面夹角示意图 Figure 4 Angle diagram of adjacent surfaces |
根据计算出的夹角θ,定义边的权值为
| $ \mathit{W}\left( \mathit{e} \right)\text{=}\left\{ \begin{align} &\text{0}\ \ \ \ \ \ \ \mathit{\theta }\in \left( \text{0, } \pi \right) \\ &\text{1}\ \ \ \ \ \ \ \ \mathit{\theta }\in \left( \pi \text{ , 2 } \pi \right) \\ \end{align} \right. $ | (2) |
为简化属性邻接图,对零件模型中边的属性进行简单量化,以权值0和1区分边的凹凸性。
3 加权属性邻接图的构造与存储通常地,图采用邻接矩阵和邻接表两种存储表示方法。传统无向图的邻接矩阵是对称的,可使用压缩存储法以节省空间,但矩阵内的值仅有0和1,在进行图匹配时容易产生较高的不确定性。图的邻接表采用指针数组表示,指针占用的空间略大,操作较为复杂容易出错。
如图 5所示,通槽1与通槽2形状不同,但是其对应的邻接矩阵却完全相同。

|
图 5 通槽及其对应邻接矩阵 Figure 5 Through slot and corresponding adjacency matrix |
为消除传统邻接矩阵在图匹配时的不确定性,避免邻接表的复杂运算操作,结合应用平台以及相关的特征识别算法,本文构造了全新的加权属性邻接图以解决上述问题。与此同时,使用链式前向星来存储加权属性邻接图的结构,链式前向星是邻接链表的数组实现方式,对于无向图实现起来简单,存储权值时可节省一半空间。定义加权属性邻接图为
| $ \mathit{G}\text{=}\langle \mathit{V}\text{, }\mathit{E}\text{, }\mathit{k}\text{, }\mathit{t}\rangle $ | (3) |
| $ \left\{ \begin{align} &\forall \mathit{\nu }\in \mathit{V}\text{, }\ \ \exists \mathit{fs}\in \mathit{FS}\text{, }\mathit{g}\left( \mathit{v} \right)\text{=}\mathit{fs} \\ &\forall \mathit{fs}\in \mathit{FS}\text{, }\exists \mathit{\nu }\in \mathit{V}\text{, }\mathit{g}\left( \mathit{fs} \right)\text{=}\mathit{v} \\ \end{align} \right. $ | (4) |
式中:V表示图G中所有节点的集合,FS为零件模型的面集合。对于集合内的任一元素v,均有零件模型中的面fs与之一一映射(以g表示映射关系),E表示图G中所有边的集合,对于集合内任一元素均有零件模型中两个相邻面fsi与fsj的公共边与之一一映射,有
| $ \forall \langle \mathit{f}{{\mathit{s}}_{\mathit{i}}}\text{, }\mathit{f}{{\mathit{s}}_{\mathit{j}}}\rangle \in \mathit{FS}\text{, }\exists \mathit{e}\in \mathit{E}\text{, }\mathit{g}\text{(}\langle \mathit{f}{{\mathit{s}}_{\mathit{i}}}\text{, }\mathit{f}{{\mathit{s}}_{\mathit{j}}}\rangle \text{)=}\mathit{e} $ | (5) |
k表示图G中面节点的属性集合,以数字1,2,3,4,…表示不同类型的面,例如1表示平面,2表示圆柱面,3表示圆锥面等。
t表示图G中边的属性集合。类似地,以数字1,2,3,4,…表示不同类型的边,例如1表示直线,2表示圆弧,3表示椭圆,同时分别以0和1表示边的凹凸性。考虑到统一表示和方便存储的需求,以两位数表示边的详细属性,十位和个位上分别存储边的类型值与凹凸性值。
根据以上所述,构造出与零件模型唯一对应的链式前向星。其在文件中的存储格式定义如图 6所示。

|
图 6 文件存储格式示例 Figure 6 Example of file sto rage format |
其中:(1)“g # N”:第N个图结构,N=0, 1, 2, 3,…如式(6)所示,自行定义第0个图结构表示一般盲槽特征(Blind slot),第1个图结构表示一般通槽特征(Throug h slot),依次类推,则
| $ \mathit{N}=\left\{ \begin{align} &0\ \ \ \ \text{feature=Blind slot} \\ &1\ \ \ \ \ \text{feature=Through slot} \\ &\text{2}\ \ \ \ \ \text{feature=Cylinder} \\ &\text{3}\ \ \ \ \ \text{feature=Cone} \\ &\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \vdots \\ \end{align} \right. $ | (6) |
(2)“V M L”:V表明该行描述对象为节点,即图中第M个节点,每一个节点都对应该特征的一个面,L为其对应的属性值。
(3)“E P Q AB ang”:E表明该行描述对象为边,表示连接节点P与节点Q的边,AB为其对应的属性值,ang为面P与面Q的夹角,其值分别设为0, 1, 2, 3, 4。具体角度值对应关系如式(7)所示,则
| $ \text{ang}=\left\{ \begin{align} &0\ \ \ \ \ \ \mathit{\theta }\in \left( 0\text{, }\frac{ \pi }{2} \right) \\ &1\ \ \ \ \ \ \mathit{\theta }\text{=}\frac{ \pi }{2} \\ &2\ \ \ \ \ \ \mathit{\theta }\in \left( \frac{ \pi }{2}\text{, } \pi \right) \\ &3\ \ \ \ \ \ \mathit{\theta }\text{=}\frac{\text{3 } \pi }{2} \\ &4\ \ \ \ \ \ \mathit{\theta }\in \left( \pi \text{ , }\frac{\text{3 } \pi }{2} \right)\cup \left( \frac{\text{3 } \pi }{2}\text{, 2 } \pi \right) \\ \end{align} \right. $ | (7) |
相应地,为常见的制造特征预定义文件数据结构并存入特征制造库中,用于后续的特征匹配,如表 1所示。
| 表 1 几种常见特征 Table 1 Several common features |
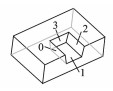
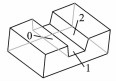
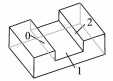
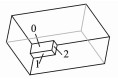
4 特征识别 4.1 特征识别算法
图形匹配算法按精度分为精确匹配和模糊匹配,特征识别所涉及到的子结构匹配即为精确匹配。假定零件模型的属性特征图为Ga,制造特征库中某一特征的属性邻接图为Gb,进而判断图Ga与图Gb是否是子图同构,即能否在图Ga中搜寻到一个子结构与图Gb完全匹配。子图同构是一个NP-complete问题,匹配算法所需时间随着输入图的扩大呈指数级增大。当前主要采用回溯算法完成图匹配,结合一些启发式规则对搜索树进行剪枝,大大降低了匹配复杂度,主要包括最早的Ullmann算法[9]、SD算法[10]、VF及VF2算法[11]。其中以VF2算法性能最好,相比于Ullman n算法,VF2算法的复杂度较小,也比较适用于处理大规模的数据。最快的同构算法是McKa y所提出的Nauty算法[12],然而Nauty算法只能用于结构完全匹配,并不能用于子结构匹配。
4.2 子图同构算法给定图Ga=(V(Ga), E(Ga), ka, ta)和图Gb=(V(Gb), E(Gb), kb, tb)。对于任意的vam, van∈V(Ga),若存在映射g,有
图 7(a)为图同构示意图,图对应关系为2-1-3→1-2-3或者2-1-3→3-2-1,确切的对应关系还需依赖节点属性作进一步判定。图 7(b)为子图同构示意图,子图对应关系有以下6种情况:2-1-3→2-1-3,2-1-3→2-1-4,2-1-3→4-1-2,2-1-3→4-1-3,2-1-3→3-1-2,2-1-3→3-1-4,确切的对应关系同样依赖节点属性判定。图 7(a)与图 7(b)中均以虚线箭头表示了其中一种对应关系。

|
图 7 图同构示意图 Figure 7 Diagram of graph isomorphism |
基于子图同构算法的制造特征识别其本质是将零件模型提取出的加权属性邻接图与预定义的特征库进行匹配,这其中同时涉及到节点与边的类型和属性信息匹配判断。综上所述,本文以VF2算法为基础,结合自定义的特征判定规则,实现制造特征的快速识别。
4.3 特征识别步骤特征识别的具体实现步骤如下:
(1) 读取图Ga,从制造特征库读取图Gi,令i=0;同时初始化匹配集M(s0)=∅。
(2) 图Ga的节点数和边数目分别为na和ea,Gi的节点数和边数目分别为ni和ei,判断ni≤na且ei≤ea。若满足条件,进入步骤(3);否则i=i+1,返回步骤(1)。
(3) 任选Ga的某一节点q1,寻找Gi中与其匹配的节点t1。若成功,将匹配对(q1, t1)存入匹配集M(s),令Num.(M(s))=1,进入步骤(4),否则选取Ga中的另一个节点q2重新寻找匹配点。
(4) 沿匹配点的邻接点继续匹配,得到新的匹配对(q, t),Num.(M(s))=Num.(M(s))+1;每次匹配不成功时均回溯至上一级匹配成功的点,尝试匹配邻接点中的其余节点。
(5) 若Num.(M(s))=ni,则表示在Ga中存在与Gi同构的子图,识别出对应特征并输出结果。
(6) i=i+1,返回步骤(1),继续搜寻Ga中是否存在制造特征库中的其他特征,直至制造特征库被完全遍历。
4.4 特征判定规则为提高特征识别匹配的效率,需对新产生的匹配对(q, t)进行可行性校验,从而实现对全部搜索空间的剪枝优化。定义Na和Ni分别为图Ga和Gi的点集,q和t分别为图Ga和Gi中的一个点。Pred(G, q)表示点q在图G中的前驱节点集合,Succ(G, q)表示点q在图G中的后继节点集合。Tain(s)和Tiin(s)分别表示状态s在图Ga和Gi中所有已经匹配节点的源点集合,Taout(s)和Tiout(s)分别表示状态s在图Ga和Gi中所有已经匹配节点的终点集合。特别地,由于本文中的加权属性邻接图为无向图,故每个节点的邻接点既是它的前驱节点又是它的后继节点,则
| $ \text{Pred } \left( \mathit{G}\text{, }\mathit{q} \right)\text{=Succ}\left( \mathit{G}\text{, }\mathit{q} \right) $ | (8) |
| $ {{\mathit{T}}^{\text{in}}}\left( \mathit{s} \right)\text{=}{{\mathit{T}}^{\text{out}}}\left( \mathit{s} \right) $ | (9) |
详细规则表示为
| $ \begin{align} &\mathit{R}{{\mathit{u}}_{\text{sem}}}\left( \mathit{s}\text{, }\mathit{q}\text{, }\mathit{t} \right)\Leftrightarrow \text{(}\mathit{q}\text{.label=}\mathit{t}\text{.label)}\wedge \text{(}\mathit{q}\text{.adjacen-} \\ &\text{cyedgenum}\ge \mathit{t}\text{.adjacencyedgenum)} \\ \end{align} $ | (10) |
| $ \begin{align} &\mathit{R}{{\mathit{u}}_{\text{pred}}}\left( \mathit{s}\text{, }\mathit{q}\text{, }\mathit{t} \right)\Leftrightarrow \text{(}\forall \mathit{{q}'}\in {{\mathit{M}}_{\mathit{a}}}\left( \mathit{s} \right)\cap \text{Pred(}{{\mathit{G}}_{\mathit{a}}}\text{, }\mathit{q}\text{), } \\ &\exists \mathit{{t}'}\in \text{Pred(}{{\mathit{G}}_{\mathit{i}}}\text{, }\mathit{t}\text{) } | \left( \mathit{{q}'}\text{, }\mathit{{t}'} \right)\in \mathit{M}\left( \mathit{s} \right)\text{)}\wedge \text{(}\forall \mathit{{t}'}\in \\ &{{\mathit{M}}_{\mathit{i}}}\left( \mathit{s} \right)\cap \text{Pred(}{{\mathit{G}}_{\mathit{i}}}\text{, }\mathit{t}\text{), }\exists \mathit{{q}'}\in \text{Pred(}{{\mathit{G}}_{\mathit{a}}}\text{, }\mathit{q}\text{) } | \left( \mathit{{q}'}\text{, }\mathit{{t}'} \right)\in \\ &\mathit{M}\left( \mathit{s} \right)\text{)} \\ \end{align} $ | (11) |
| $ \begin{align} &\mathit{R}{{\mathit{u}}_{\text{in}}}\left( \mathit{s}\text{, }\mathit{q}\text{, }\mathit{t} \right)\Leftrightarrow \text{Card(Succ(}{{\mathit{G}}_{\mathit{a}}}\text{, }\mathit{q}\text{)}\cap \mathit{T}_{\mathit{a}}^{\text{in}}\left( \mathit{s} \right)\text{)}\ge \\ &\text{Card(Succ(}{{\mathit{G}}_{\mathit{i}}}\text{, }\mathit{t}\text{)}\cap \mathit{T}_{\mathit{i}}^{\text{in}}\left( \mathit{s} \right)\text{)} \\ \end{align} $ | (12) |
其中:式(10)为语义判定规则,保证了候选匹配对(q, t)两节点对应的label值必须相同,且节点q的邻接边数目必须不小于节点t的邻接边数目,否则该匹配对无效,循环判定下一匹配对。式(11)为同构规则,确保加入新的匹配对后两个子图仍旧同构。式(9)表示q在图Ga中的所有前驱节点,均能在图Gi中t节点的前驱节点找到相应点与之对应。反之,t在图Gi中的所有前驱节点,亦均能在图Ga中q节点的前驱节点找到相应点与之对应。由于无向图的特性(式(8)),可以发现后继节点的判定规则与式(11)完全一致,故不另行再作判定。式(12)为剪枝规则,Card表示求该集合中元素的个数。式(12)表示q在Tain(s)中的前驱数目必须大于等于t在Tiin(s)中的前驱数目,后继节点亦不做重复判定。
以相同的图数据结构为基准,测试Ullmann算法、VF2算法和MFGA三者在不同节点数下的运行耗时,测试结果如图 8所示。显然,当节点数相同时GSGI运行耗时明显优于Ullmann与VF2算法。

|
图 8 算法运行耗时对比 Figure 8 Runn ing time comparison of several algorithms |
通过以上规则的限制,对同构算法进行优化,可以有效减少候选匹配对的数目,从而加快了算法的运行速度,优化其执行效率,最终该方法可实现对简单特征和部分复杂特征的有效识别。
5 特征识别实例在Creo2.0平台上构建零件模型,使用M icrosoft Visual Studio 2010编写算法程序,结合Pro/Toolkit二次开发函数库对输入零件模型的所需信息及相关属性进行提取,对文中所提的基于图和特征子图算法的制造特征识别方法进行验证,给出示例零件模型如图 9(a)所示。由于零件较为复杂,故仅给出其对应加权属性邻接图的部分文本数据行,如图 9(b)所示。

|
图 9 示例零件及各项数据内容 Figure 9 Sample part and relevant data contents |
6 结束语
本文提出了应用于Creo零件模型的制造特征快速识别方法。通过定义加权属性邻接图和文件数据结构,结合子图同构算法对零件模型进行特征识别,此外为算法添加了一系列的判定规则,以提高识别速度,减少程序运行的等待时间。该方法可实现对零件模型制造特征的有效识别,最后通过模型实例验证了该方法的可行性。
| [1] |
BABIC B, NESIC N, MILJKOVIC Z.
A review of automated feature recognition with rule-based pattern recognition[J]. Computers in Industry, 2008, 59(4): 321–337.
DOI:10.1016/j.compind.2007.09.001
|
| [2] |
JOSHI S, CHANG T C.
Graph-based heuristics for recognition of machined features from a 3D solid model[J]. Computer-Aided Design, 1988, 20(2): 58–66.
DOI:10.1016/0010-4485(88)90050-4
|
| [3] |
MA Lujie, HUANG Zhengdong, WANG Yanwei.
Automatic discovery of common design structures in CAD models[J]. Computers & Graphics, 2010, 34(5): 545–555.
|
| [4] |
SUNIL V B, AGARWAL R, PANDE S S.
An approach to recognize interacting features from B-Rep CAD models of prismatic machined parts using a hybrid (graph and rule based) technique[J]. Computers in Industry, 2010, 61(7): 686–701.
DOI:10.1016/j.compind.2010.03.011
|
| [5] |
田富君, 田锡天, 耿俊浩, 等.
基于轻量化模型的加工特征识别技术[J]. 中国机械工程, 2010, 18: 2212–2217.
TIAN Fujun, TIAN Xitian, GENG Junhao, et al. Machining feature recognition based on lightweight model[J]. China Mechanical Engineering, 2010, 18: 2212–2217. |
| [6] |
付鹏, 苑伟政.
基于STEP的特征识别技术及其实现[J]. 中国机械工程, 2010, 11: 1334–1337.
FU Peng, YUAN Weizheng. Technology and implement process of feature recognition based on STEP[J]. China Mechanical Engineering, 2010, 11: 1334–1337. |
| [7] |
莫蓉, 刘蔚昕, 万能, 等.
三维工序模型加工特征环境匹配[J]. 机械科学与技术, 2015, 34(4): 549–554.
MO Rong, LIU Weixin, WAN Neng, et al. Study on the environmental matching of machining feature for 3D process model[J]. Mechanical Science and Technology for Aerospace Engineering, 2015, 34(4): 549–554. |
| [8] |
王军, 欧道江, 舒启林, 等.
基于STEP-NC的相交特征识别技术[J]. 计算机集成制造系统, 2014, 20(5): 1051–1061.
WANG Jun, OU Daojiang, SHU Qilin, et al. Interacting feature recognition technology based on STEP-NC[J]. Computer Integrated Manufacturing Systems, 2014, 20(5): 1051–1061. |
| [9] |
ULLMANN J R.
An algorithm for subgraph isomorphism[J]. Journal of the ACM (JACM), 1976, 23(1): 31–42.
DOI:10.1145/321921.321925
|
| [10] |
SOMKUNWAR R, VAZE V M. A novel approach for graph isomorphism: Handling large graphs[C]//Recent Trends in Electronics, Information & Communication Technology (RTEICT). [S. l.]: IEEE, 2017: 1242-1247. |
| [11] |
CORDELLA L P, FOGGIA P, SANSONE C, et al.
A (sub) graph isomorphism algorithm for matching large graphs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(10): 1367–1372.
DOI:10.1109/TPAMI.2004.75
|
| [12] |
JVTTNER A, MADARASI P.
VF2++- an improved subgraph isomorphism algorithm[J]. Discrete Applied Mathematics, 2018, 242: 69–81.
DOI:10.1016/j.dam.2018.02.018
|